101 on AKS defaults, nodes, pods and stuff

I know this blog post is long overdue. No excuses. Been to busy lazy.
Thanks for being here, let’s start with 101 on AKS defaults, nodes, pods and stuff.
I’m sure you all know that AKS is a hosted Kubernetes service from Microsoft. Azure manages Kubernetes master nodes for us, and we only need to manage and maintain the user nodes. And we will only pay for the user nodes. In case you’re interested on building a self-managed Kubernetes playground cluster, see my previous post. In this blog I will introduce the basics and guide you through a provisioning of an AKS cluster using Azure CLI.
Probably the easiest way to get started is running just the following two commands:
az group create --name myResourceGroup --location westeurope
az aks create --resource-group myResourceGroup --name myAKSCluster
I’m not going to use that approach, but if you’re eager to get kicking the tires of a AKS cluster, you can get started with Microsoft’s AKS quickstart and run those commands. If you did use the previous commands to get started, you just deployed the cluster using default settings. Let’s have a look of some of the defaults, and I’ll introduce some of the other options as well.
Networking
I’m not going to go much into details as this is a 101 post, but there are two options for AKS network models, kubenet (basic and default) and Azure CNI (advanced). One fundamental difference between the two is how IP addresses are allocated to pods. With kubenet, the nodes get an IP address from the virtual network subnet they are connected to, and pods receive an IP address from different address space. Traffic is NAT’d to node’s IP address. With Azure CNI, every pod gets an IP address from the same subnet as the nodes and pods can be accessed directly. This means we need more planning with IP addresses not to run out of IP addresses. This might prevent adding new nodes when scaling or upgrading a cluster.
If you did deploy the cluster with default options, you deployed the cluster with kubenet and Azure also provisioned a virtual network for you with 10.0.0.0/8 address range. This block contains one subnet (10.240.0.0/16) for the worker nodes. Along came default subnets for Pods (10.244.0.0/16), Services (10.0.0.0/16) and Docker bridge (172.17.0.1/16). while cluster’s DNS service IP was set to 10.0.0.10. When you adjust these defaults to meet your needs and environment, note that cluster’s DNS service IP address must be within the Kubernetes service address range.
Note! If you need to use Windows Server node pools, you must use Azure CNI as kubenet is not available for Windows Server containers.
I’m going to use Azure CNI (--network-plugin azure) in the later demo environment, as I don’t need to be afraid of running out of IP addresses. It’s also worth mentioning that Microsoft’s best practices recommend Azure CNI when using existing virtual networks or on-premises networks.
Nodes
To be able to run applications and supporting services, we need a node (Azure virtual machine running Kubernetes node components and container runtime). We can run one or more nodes in a cluster. Preferably more than one, so that we can meet the minimum level of availability and reliability for the workloads. Three nodes is recommended for system node pool, and minimum of two for user node pools. By default when deploying AKS, the cluster ends up with three system nodes. We can change it through --node-count parameter.
Note! System pools must have at least one node, while user node pools may have zero or more nodes.
Default virtual machine size for Linux clusters is Standard_DS2_v2 (2vCPU, 7GB), while minimum requirement of a VM SKU for system node pools is 2 vCPUs and 4GB RAM at the time of the writing in October 2020. We can use --node-vm-size to change the size of the VMs. When choosing the optimal size for a worker node VM, consider the amount of pods running on one node and the requirements for those pods. Note that by default the maximum pods allowed per node varies between network model. With kubenet, the nodes will by default have maximum number of pods set to 110, and with Azure CNI max is set to 30 pods. Maximum number of pods per node can be configured (--max-pods) at cluster deployment time or when adding new node pools into cluster. The maximum value is 250 pods per node.
When deploying AKS cluster, Azure creates by default a second resource group for the worker nodes and network resources. By default the name of the resource group is MC_resourcegroupname_clustername_location. Be sure to check out what’s in the resource group after the cluster deployment. If you don’t like the name of the resource group, it can be customized at the time of the cluster creation by using --node-resource-group parameter. You will need to install aks-preview (az extension add --name aks-preview) extension version 0.3.2 or later.
Kubernetes version
As Azure manages the master node for us, we can’t just pick whatever Kubernetes version we want to use. Current version by default is set to 1.17.11, but we can select another one using --kubernetes-version. To learn which versions are available in each region, we can search them with az aks get-versions --location westeurope. Note that different regions might offer different versions.
As a best practice, Kubernetes version of the cluster should be regularly upgraded. Not only to get bugfixes and security updates, but also to get new features introduced in the latest versions.
You can check available upgrades for your cluster with az aks get-upgrades --resource-group myResourceGroup --name myAKSCluster and upgrade the cluster with az aks upgrade. Please test the upgrades first in dev and test environments!
Service Principal vs Managed Identity
AKS cluster requires either an Azure AD service principal or a managed identity. Why? To interact with Azure APIs, for example to dynamically create and manage Azure resources. When deploying AKS cluster with default options, a service principal is automatically created. Service principal can also be created manually, and assigned during AKS cluster creation with --service-principal <appId> --client-secret <password> parameters. Service principal for the AKS cluster can be used to access other Azure resources by delegating permissions to those resources using role assignments. By default service principal credentials are valid for one year and needs to be renewed to keep the cluster working.
Managing service principals, and their credentials, adds complexity, which is why I recommend using managed identities instead.
Managed identity can be enabled (--enable-managed-identity) for the cluster only at the time of the cluster creation. Note that it’s not possible to migrate existing AKS clusters to managed identities.
Azure AD integration
By default AKS is not integrated with Azure AD, either for user authentication or for controlling access to cluster resources, but we can do that. There are even two ways to do this (the legacy way and the new way), I suggest to go with the new :). You can use --enable-aad --aad-admin-group-object-ids <id> while deploying the cluster, or later if you want to enable the integration for an existing cluster. We can also configure Kubernetes RBAC to control access to namespaces and cluster resources based a user’s Azure AD identity or group membership.
Note! Once AKS-managed Azure AD integration is enabled it can’t be disabled.
Monitoring
We all know how important it is to have logging and monitoring in place. Otherwise we would be running blind when troubleshooting performance issues. We can achieve visibility to memory and processor utilization of nodes, controllers and containers using Azure Monitor for containers. By default monitoring is not enabled, but can be enabled with --enable-addons monitoring. In the backgroung this will make use of Log Analytics workspace (we can specify existing with --workspace-resource-id) and containerized Log Analytics agent for Linux.
Access to server API
Enough is enough, I hear you say.
This is the last thing (pinky swear) before we jump into running some pods and stuff in AKS. By default the AKS cluster is reachable through public internet. API server address being something like myaksclust-myresourcegroup-4b47dc-7e205e4b.hcp.westeurope.azmk8s.io. Certainly we can and we should restrict access to API server by setting authorized IP ranges (--api-server-authorized-ip-ranges) to limit which IPs can connect.
Securing access to the API Server is one of the most important things to do to secure an AKS cluster. Restrict access with authorized IP ranges, and use Kubernetes RBAC together with Azure AD-integration.
Note! AKS cluster uses by default a standard load balancer which can be used to configure outbound gateway. When enabling API server authorized IP ranges during cluster creation, public IP of the cluster is also allowed by default in addition to the ranges specified.
What if we wanted to restrict the traffic between API server and the nodes to remain on the private network only? We absolutely can do that with private AKS cluster (--enable-private-cluster). With private cluster there’s no public IP address for API server endpoint. This means that to manage the API server, we need to have access to the AKS cluster’s virtual network. Be it a VM in the same vnet as the AKS cluster, or access through vnet peering, ExpressRoute or VPN. We are not going to deploy a private AKS cluster now, but I might write another post on that one later.
Note! You can’t convert existing AKS cluster to private cluster.
Demo setup
Finally, it’s time to push the gas pedal and deploy us an AKS cluster. I’ll personally do this from the Azure Cloud Shell, using some of the parameters we learned earlier.
AKS=aks-building4-dev
RG=rg-aks-building4-dev
NODERG=rg-aks-nodes-building4-dev
LOC=westeurope
MYIP=$(curl ifconfig.me) // to fetch the public IP address of the Cloud Shell session.
az group create --name $RG --location $LOC
az aks create \
--resource-group $RG \
--name $AKS \
--location $LOC \
--node-count 2 \
--kubernetes-version 1.18.8 \
--network-plugin azure \
--enable-managed-identity \
--enable-addons monitoring \
--api-server-authorized-ip-ranges $MYIP/32
After a while my new and shiny AKS cluster is up and running.
Connecting to the cluster
As Cloud Shell already includes all the necessary tools to connect to the AKS cluster, we can get our credentials with az aks get-credentials --resource-group $RG --name $AKS which downloads the credentials and configures kubeconfig for us.
Let’s try connecting to the cluster kubectl get nodes. We should be getting a response such like this:
NAME STATUS ROLES AGE VERSION
aks-nodepool1-39782595-vmss000000 Ready agent 51m v1.18.8
aks-nodepool1-39782595-vmss000001 Ready agent 51m v1.18.8
If we then try kubectl get pods, we are not seeing any. Well obviously we don’t see any as we haven’t deployed pods to default namespace. We can list the system pods runnign in namespace kube-system by kubectl get pods -n kube-system. Now we should get some system pods listed, among them should be at least coredns, azure-cni and kube-proxy.
Deploying some pods and stuff
As you probably know a Pod is the smallest deployable unit of computing that can be created and managed in Kubernetes. In Kubernetes Pods are usually created using workload resources such as Deployments. So let’s kick off a deployment using a sample deployment kubectl create deployment kubernetes-bootcamp --image=gcr.io/google-samples/kubernetes-bootcamp:v1. In the background a suitable node will be selected and a pod will be scheduled to run there.
If we then run kubectl get pods we can see that we now have
NAME READY STATUS RESTARTS AGE
kubernetes-bootcamp-6f6656d949-4nt9c 1/1 Running 0 44s
We are rocking!
You can also go and see the same information from the Azure Portal. Find your AKS cluster and choose Workloads (preview) feature under Kubernetes resources. If you get a warning about that you need Enable Kubernetes resource view, have a look of the PI server authorized IP ranges. Your client computer’s IP address might not be included. Not at least if you have been following along my example and only allowed the Cloud Shell’s public IP address.
In case you need to make a change to the API server authorized IP ranges at any time, you can update the ranges using az aks update --resource-group $RG --name $AKS --api-server-authorized-ip-ranges ip-address1/32,ip-address2/32. This should give you access to the same information on Azure Portal as well. For example if we look at the list of deployments, we can find kubernetes-bootcamp that we just created.
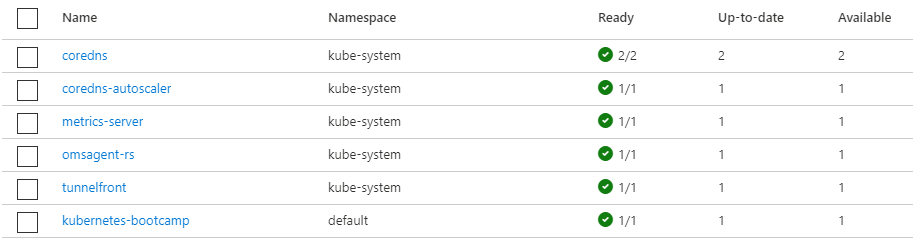
If we want to find out the node where the pod is running, we can use kubectl get pods -o wide, which should output information about the node.
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
kubernetes-bootcamp-6f6656d949-4nt9c 1/1 Running 0 6m 10.240.0.46 aks-nodepool1-39782595-vmss000001 <none> <none>
Accessing and exposing the pods
So what should we do access the pod? For starters we can connect through the pod’s IP address as we are using Azure CNI. Then it’s just a matter of entering http://{ip-address-of-the-pod}:8080 into a web browser, curl or whatever, and I’ll get greeted with: “Hello Kubernetes bootcamp! | Running on: kubernetes-bootcamp-6f6656d949-4nt9c | v=1”.
We can elso expose the pod through a NodePort (kubectl expose deployment/kubernetes-bootcamp --type=NodePort --port 8080). To be able to access it, we need to have a client machine which can access either of the nodes. I happen to have a jumpbox VM running on a vnet, which I peered with the AKS vnet, so I can use that. By running kubectl get svc kubernetes-bootcamp I can get the port of the NodePort (30046).
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes-bootcamp NodePort 10.0.250.73 <none> 8080:30046/TCP 22s
I will then need an IP address of one of the nodes. I can get them by kubectl get nodes -o wide. Then it’s just a matter of entering http://{ip-address-of-node}:30046 into a web browser, curl or whatever, and I’ll be once again greeted with: “Hello Kubernetes bootcamp! | Running on: kubernetes-bootcamp-6f6656d949-4nt9c | v=1”.
Let’s try one more approach. Let’s first delete the service (kubectl delete service kubernetes-bootcamp) and create a new one. This time let’s expose the deployment with a public Azure LoadBalancer (kubectl expose deployment/kubernetes-bootcamp --type=LoadBalancer --port 8080). Then we can run kubectl get svc kubernetes-bootcamp again to get the public ip (EXTERNAL-IP from the output) address of the exposed service. This time let’s hit http://{EXTERNAL-IP}:8080 and we’ll receive the same greeting. Nice work!
Replicas
Let’s switch gears a little. Currently we have only been running one single pod, so it would be good to have some more replicas to provide some resilience for our application. Let’s do that now, and scale the deployment to four replicas (kubectl scale deployments/kubernetes-bootcamp --replicas=4). We can check the status by kubectl get deployment/kubernetes-bootcamp. It should soon show that we have four replicas running. If we now keep hitting http://{EXTERNAL-IP}:8080, we should start getting responses from different pods. Looks like it works!
Let’s now delete one of the pods. I’ll use the first one (kubectl delete pod kubernetes-bootcamp-6f6656d949-4nt9c). While we get rid of that one pod, Kubernetes deploys a new pod to replace the deleted one. All because we set the desired replica count to four. Ain’t that nice :). If we want to permanently remove some of the pods, we should scale down the desired replica count.
When we initally created the Deployment, a ReplicaSet was rolled out. And it is the job of the ReplicaSet to create and watch over the pods. We can check the ReplicaSets in a cluster with kubectl get replicasets.
Updating application
For now we have been running v1 of the application. Let’s update the version to v2 with kubectl set image deployments/kubernetes-bootcamp kubernetes-bootcamp=jocatalin/kubernetes-bootcamp:v2. Kubernetes will rollout the updated version to the pods, so if we once again hit the application, we will be greeted with v2 (“Hello Kubernetes bootcamp! | Running on: kubernetes-bootcamp-86656bc875-67l4r | v=2”) of the application. You might have noticed that the hash part of the pod’s name has changed from 6f6656d949 to 86656bc875. Same hash should be visible in the name of the replicaset. You can once again check the ReplicaSets in a cluster with kubectl get replicasets.
Once more, this time let’s use v10 (kubectl set image deployments/kubernetes-bootcamp kubernetes-bootcamp=gcr.io/google-samples/kubernetes-bootcamp:v10). Let’s check the deployment status by (kubectl get deployments).
Hmmm, what’s happening?!?
We seem to be stuck here, with three pods ready, although the desired count is four.
NAME READY UP-TO-DATE AVAILABLE AGE
kubernetes-bootcamp 3/4 2 3 40m
If we check the pods (kubectl get pods), we can see that two pods in status ImagePullBackOff. We can then use kubectl describe pods/{pod-name-here} to see more details about the pod’s events, which confirms to us that there is no v10 of the image. Let’s roll back the deployment to v2 by running kubectl rollout undo deployments/kubernetes-bootcamp. We can then check that everything is back to normal by running (kubectl get deployments). Output should report us that four out of four pods are now ready to serve consumers.
Monitoring
Because monitoring-addon was enabled for this cluster, we can go ahead and check the metrics of kubernetes-bootcamp containers, and drill in to the details if needed. Head into the Portal and click Insights under Monitoring.
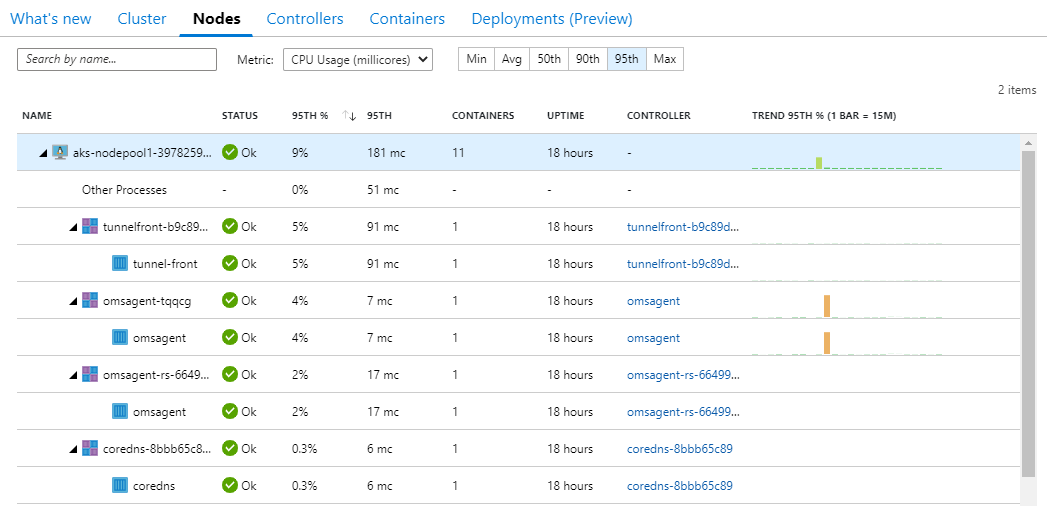
That’s it for this post.
Removing resources
So, we have reached the end of the post, and it’s time to remove the resources to avoid unnecessary costs.
az group delete --name rg-aks-building4-dev --yes --no-wait
Summary and what’s next
I hope you found my 101 AKS post useful. I tried to introduce you to some of the basics and defaults of AKS cluster deployment. And we also got to play around, kick the tires and see how we can interact with pods.
I think I’d next like to do a blog post on private AKS cluster and/or Kubernetes RBAC with Azure AD integration. If you have a preference or other ideas, let me know.
Maybe you want something else or want to leave a comment? Reach out to me on LinkedIn or Twitter.
Take care of each other and be safe.